Analiza powłamaniowa w systemie Linux
Brute force
Do ataków brute force popularnym narzędziem jest hydra, system Kali Linux jest domyślnie w nie wyposażony i nie trzeba nic dodatkowo instalować. Aby móc analizować jakiś system należy go zaatakować - wygenerować sobie logi. W tym celu możemy wykorzystując narzędzie hydra zaatakować drugą maszynę wirtualną. Po przeprowadzeniu ataku możemy sprawdzić logi, dostępne są w pliku:
1
/var/log/auth.log
plik ten możemy po prostu wypisać, lub otworzyć sobie narzędziem less. W logach doskonale będzie widać próbę ataku na system - wiele prób połączenia się które zakończyły się niepowodzeniem, aż w końcu będzie poprawne logowanie (choć nie musi być, w końcu atakujący nie musiał koniecznie odgadnąć hasła). Przykładowy plik może wyglądać następująco: 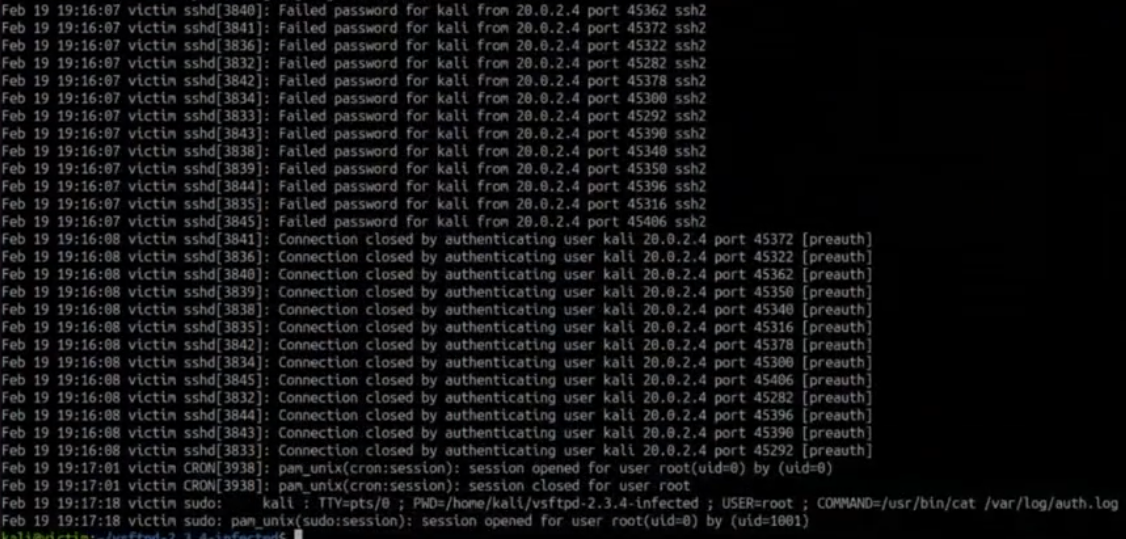
SQL injection
Atak SQL injection może być zautomatyzowany narzędziem SQL map. Jeśli atak SQL injection miał charakter webowy to śladów tego ataku powinniśmy szukać w /var/log/apache2/access.log, przykładowy plik:  w tym przypadku idealnie widać wykorzystane narzędzie, również bardzo często zamiast SQL mapa może pojawiać się tam curl. Jednak sprawni atakujący będą w stanie podszyć się pod inną aplikację/program.
w tym przypadku idealnie widać wykorzystane narzędzie, również bardzo często zamiast SQL mapa może pojawiać się tam curl. Jednak sprawni atakujący będą w stanie podszyć się pod inną aplikację/program.
WEB shell
Możemy sobie wyobrazić, że posiadamy/testujemy jakąś WEB aplikację i z jakiegoś powodu aplikacja ta korzysta z funkcji exec. Bardzo często w takich przypadkach atakujący/tester może po prostu dokleić dodatkową komendę która zostanie wykonana na serwerze. W typ przypadku śladów ataku również szukamy w /var/log/apache2/access.log, ważne jest aby nasz serwer był tak skonfigurowany aby logować całe komendy przesyłane na serwer - dzięki temu znając popularne nazwy web shell możemy łatwiej parsować ten plik podczas analizy.
Podsumowując:
- brute force: aby się zabezpieczyć należy ograniczyć dostępność do Internetu, czyli:
- zmiana portu (nie jest to dobry pomysł - generalnie nie działa)
- komunikacja po VPN
- dodatkowy czynnik logowania
- zabezpieczenie metod uwierzytelniania - stosujemy jakiś monitoring usługi i wykrywany oraz blokujemy próby ataku brute force. Powinno się stosować uwierzytelnianie wieloskładnikowe, logowanie przy pomocy certyfikatów
- mitm/sql inj:
- wykrywanie zagrożeń: monitorowanie anomalii, alarmowanie oraz reagowanie
- ograniczanie komunikacji: separacja sieci, szyfrowanie połączeń, zaufana hosty i użytkownicy, relacje zaufania i certyfikaty
- eksploity:
- awarness: nabywanie wiedzy o zagrożeniach, minimalizacja uprawnień i rozliczalność, zarządzenie konfiguracją, testy penetracyjne i wewnętrzne
- ograniczenie komunikacji: separacja sieci, szyfrowanie połączenia, zaufane hosty i użytkownicy
aby budować w naszym systemie przyjemne/przydatne logi warto skorzystać z następujących ustawień:
1
CustomLog${APACHE_LOG_DIR}/custom.log \ "%h %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-agent}i\" \"%{Cookie}i\""
dzięki temu będziemy posiadali rozbudowane logi, wraz z zapisanymi wartościami ciasteczek.
- webshell:
- wprowadzenie modelu zero trust: ograniczenie uprawnień do minimum, mod_security, siem
DFIR - Digital Forensic and Incident Response
Łańcuch killchain:
- Rekonesans: wykorzystanie jakiegoś skanera do znalezienia podatności,
- Uzbrajanie: mając podatność tworzymy/znajdujemy eksploit,
- Dostawa: dostarczamy eksploit do atakowanego systemu - wysłanie pliku jako załącznik, atak na aplikację webową,
- Eksploitacja: zdobycie jakiegoś dostępu,
- Utrzymanie: pozostawienie wejścia do systemy np. przed dodanie kluczy ssh,
- Command and Control: czasem możliwe jest też przejęcie kontroli nad atakowanym systemem.
- Eksfiltracja/akcje: eksfiltracja danych, usunięcie danych, szyfrowanie, wykradzenie danych. W ostatnim czasie częściej się spotyka z wykradaniem danych niż ich szyfrowaniem - coś takiego trudniej jest wykryć więc przestępcy mają większą skuteczność. W przypadku szyfrowania/wykradzenia danych przestępcy żądają okupu w zamian za klucz do odszyfrowania lub nie opublikowanie wykradzionych danych.
Kolejnym rodzajem zagrożenia jest APT (Advanced Persistent Threat) rozumiane jest to jako zestawienie wiedzy narzędzi które nie koniecznie są szybkie, są natomiast skuteczne. Warto jest pamiętać o stronie attack-navigator dzięki niej wybierając odpowiednie opcje możemy zidentyfikować grupę APT która wykonuje/wykonała atak. Jest to bardzo przydatne do reportu analizy powłamaniowej. Jeśli zidentyfikowaliśmy, że atakuje nas jakaś grupa APT powinniśmy powiadomić CERT - grupy za grupami APT często stoją jakieś państwa.
Killchain w praktyce
- Initial access: jakiś loader który pobiera malware
- Discovery: netstat, adresacje ip
- Credential access: wykorzystanie volatility
- Persistence: nc, systemd
- Data exfiltration: scp, rsync
Analiza powłamaniowa:
Zbieranie dowodów: logów, zrzutów pamięci i przeprowadzenie na nich analizy - czyli zebrania dowodów, jednak:
- nie wiadomo kiedy zdarzy/zdarzył się incydent,
- nie wiadomo jakiej części infrastruktury dotknie,
- nie wiemy, które dane i co się z nimi stanie. W przypadku jeśli jest już po ataku bardzo ważny jest wywiad, konkretnie wywiad z osobami które brały udział w zdarzeniu bezpośrednio - potrafi podać znacznik czasu, podać adres IP generalnie cokolwiek co może nam pomóc.
Analiza powłamaniowa dzieli się na cztery części:
- file system forensics: co się zmieniło w plikach, czy atakujący stworzyli nowe, usunęli lub zmienili jakieś pliki (narzędzia: dd, ftk, sleuth | autopsy, foremost | ext4magic, testdisk, rkhunter, aide),
- memory forensics: mamy tutaj wszystkie zdarzenia, wszystkie sesje, czasem można nawet wyjąć klucz deszyfrujący do ransomware (narzędzia: lime | avml | fmem, volatility | rekall, grr),
- network forensics: jeśli zbierane są logi z sieci również mogą znajdować się w nich ważne informacje (narzędzia: wireshark | tshark |cap, tcpdump, snort, bro | zeek | zui),
- log analysis: potwierdzenie, że zdarzenie miało miejsce (narzędzia: logwatch | ELK, goaccess, webalizer | AWstats, graylog).
Na podstawie analizy powłamaniowej powstaje raport i raport jest wiążący. Raport powinien zawierać informacje pewne, dodatkowo analityk powinien być bezstronny. Raport ma wskazywać fakty, a nie żadne domysły!
Normy
Generalnie w analizie powłamaniowej nie muszą być stosowane żadne normy, natomiast w informatyce śledczej bardzo często sąd wskazuje normę zgodnie z którą dowody powinny być zbierane. Warto zapoznać się z dokumentem RFC 3237.
Świetne narzędzie - właściwie gotowy system do prowadzenia analizy powłamaniowej: tsurugi remnux.
Analiza powłamaniowa, co może się przydać
- ruch sieciowy: wymaga dużej przestrzeni dyskowej - często może być to wręcz nie realne, aby zbierać i stosować retencję danych przez jakiś czas. Dodatkowo jest też duży szum i dużo informacji nadmiarowych.
- ids/ips: nie musimy zbierać całego ruchu - powstają nam jakieś alerty i to właśnie je zbieramy.
- siem: zbieramy informacje kluczowe, które mogą być korelowane, darmowym dobrym siem jest security onion.
Incident response:
Przygotowanie do wykrycia incydentów:
- minimalne kroki dotyczące przygotowanie infrastruktury IT: zabezpieczenie, odcinanie konkretnych węzłów
- minimalne kroki dotyczące przygotowanie pracowników: szkolenie pracowników - przykładowo uświadomienie ich, że jeśli dojdzie do infekcji ransomware nie zamykać komputera - odcinamy sieć, a nie wyłączamy komputer. Ponieważ wyłączając komputer zacierane są ślady.
Etapy obsługi incydentu:
- wykrycie
- potwierdzenie
- ograniczenie wpływu incydentu
- usunięcie skutków i zebranie dowodów: odtworzenie systemów z kopii zapasowych,
- odpowiedź na incydent: powstanie raportu, przeliczenie analizy ryzyka, powinna być prowadzona ewidencja takich raportów.
Prowadzenie ewidencji incydentów, ewidencja powinna zawierać następujące dane:
- data wykrycia,
- status,
- daty zmiany statusu,
- opis incydentu,
- podjęte działania i przez kogo,
- zalecenia,
- przeliczona analiza ryzyka
Aby stworzyć kopię jeden do jeden można wykorzystać narzędzie dd:
1
dd if=/dev/sdX of=/dev/sdY, status=progress
nie powinniśmy dodawać dodatkowych opcji, ponieważ przez ich wykorzystanie prawidłowa kopia binarna może nie zostać wykonana - dodatkowe opcje mogą wpłynąć na wykonywaną kopię. Również później podczas pracy powinniśmy kontrolować sumy kontrolne (md5, sha256).